Failed to start switch root… GRUB shell dopo aggiornamento – Server CentOS
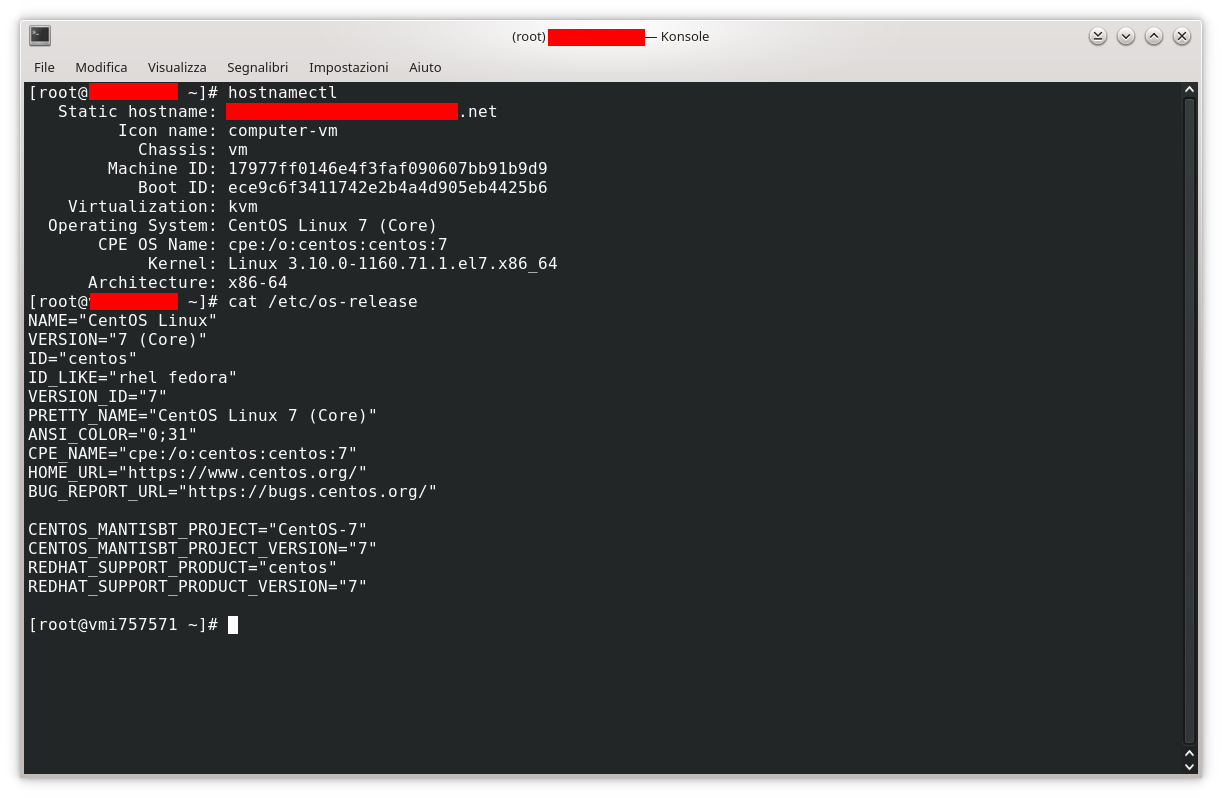
Scenario: server con distribuzione GNU/Linux CentOS, di preciso centos-release-7-9.2009.1.el7.centos.x86_64. La conoscenza della versione in uso la si può ottenere, com’è consuetudine in ambiente GNU/Linux, impartendo diversi comandi. Nel caso in esame per una CentOS l’informazione è ottenibile con:
- rpm –query centos-release – fornirà in uscita centos-release-7-9.2009.1.el7.centos.x86_64;
- cat /etc/centos-release – il suo output vede CentOS Linux release 7.9.2009 (Core);
- cat /etc/system-release – lettura da file differente ma risposta al comando pari al precedente ovvero CentOS Linux release 7.9.2009 (Core);
Altri due possibili opzioni vedono i comandi hostnamectl e cat /etc/os-release che forniranno in uscita i seguenti output:
Il tutto è iniziato allorquando le periodiche verifiche hanno segnalato un aggiornamento di 29 pacchetti (kernel e bootloader Grub compresi) che eseguo sistematicamente via SSH (Secure SHell) con l’usuale comando yum update a cui fa seguito puntualmente un riavvio del server, sebbene in diverse occasioni non sarebbe nemmeno necessario, ma tant’è…
L’aggiornamento del kernel riguardava il passaggio dalla versione 3.10.0-1160.62.1.el7.x86_64 alla versione 3.10.0-1160.66.1.el7.x86_64. Al riavvio qualcosa è andato storto! Si potrebbe pensare che durante la fase di aggiornamento potrebbe essere avvenuta una corruzione di qualche file di configurazione, una errata/non corretta (auto)configurazione di uno specifico file di configurazione, una cancellazione, o malfunzionamento del sistema di aggiornamento, a causa di un bug del sistema e molto altro ancora …ma cosa di preciso?
In poco più di 9 mesi con questo nuovo VPS (Virtual Private Server) è la seconda volta che qualcosa va storto. Alla prima non avevo accesso via VNC (Virtual Network Computing) tanto meno via SSH (Secure SHell) quindi, gioco forza, dovetti aprire un ticket con il servizio clienti della società di hosting proprietaria del server.
Questa volta nessun accesso via SSH (e non poteva essere diversamente visto che il server non si avviava!) però c’è l’accesso via VNC. Alleluja! E allora perché aprire un ticket? Uso GNU/Linux in maniera continuativa da “solo” 20 anni (anno 2002, installai la storica Mandrake 8.1 seguita in dual boot dopo qualche settimana da una Slackware 8.0, che scalzò l’allora Microsoft Windows XP dal computer. Il Boot Manager era GAG 🙂 ), pertanto non ci sono scusanti, devo risolvere il problema da solo!
Indice - Table of Contents
Il bootloader GRUB/GRUB2
Acronimo di GRand Unified Bootloader, GRUB è un bootloader modulare oggi arrivato alla versione 2. È in grado di permettere l’avvio di diverse piattaforme PC BIOS e PC UEFI così come sistemi operativi liberi (e.g. i *BSD e Linux) e proprietari (DOS, Microsoft Windows e OS/2).
Il bootloader GRUB 2, così sono chiamate tutte le versioni di GRUB superiori alla 1.98, è una completa riscrittura del “vecchio” GRUB detto Legacy (versione 0.97 e precedenti) e in quanto tale porta con se svariate modifiche. La più rilevante è nella dinamica di funzionamento che vede una riorganizzazione dei tipici file immagine che caratterizzavano GRUB Legcy unitamente agli “stadi di avvio”, noti con le sigle 1, 1.5 e 2, che in GRUB 2 non esistono più! Per essere precisi la fase 1 di GRUB Legacy e GRUB 2 sono molto simili, di fatto svolgono la medesima funzione; leggere il settore di avvio (512byte) dell’MBR in un PC BIOS utilizzando l’immagine boot.img. Lo stage 2 in GRUB 2 non esiste come unica immagine, così come era presente in GRUB Legacy, ma vengono caricati specifici moduli a run-time (tempo di esecuzione) dal percorso /boot/grub2/ dopo che è stata caricata l’immagine del core GRUB 2 di nome core.img creata dinamicamente dall’immagine del kernel dal comando grub-mkimage (man grub-mkimage per approfondimenti) il quale, tra le altre cose, viene lanciato ad esempio nel momento in cui deve essere installato il bootloader in parola unitamente al comando comando grub-install (man grub-install per maggiori informazioni), oppure in presenza di aggiornamenti del kernel al fine di aggiungere la riga di avvio nel file di configurazione.
Non solo la dinamica, ma cambi anche nella procedura di avvio; in maniera predefinita GRUB 2 visualizzerà direttamente la schermata di accesso (login) e nessun menù verrà mostrato a meno di mantenere premuto nei primissimi istanti di avvio il tasto Shift destro oppure, a seconda della configurazione, il tasto Esc.
La richiamata modularità di GRUB 2 permette l’aggiunta di moduli separati in grado di supportare diverse soluzioni di archiviazione e specifiche tecnologie come ad esempio il supporto per vari filesystem (e.g. ext2/ext3/ext4, NTFS, btrf e zfs), del sistema di gestione LVM (Logical Volume Manager) fino ai dispositivi RAID (Redundant Array of Independent Disks) software. Tali moduli terminano con il suffisso .mod e possono essere richiamati/caricati utilizzando il comando insmod alla stregua di un modulo del kernel ad esempio nella modalità a linea di comando (CLI, Command Line Interface). La modalità CLI è meglio nota con il termine di GRUB Shell poiché permette, tra le altre cose, di eseguire comandi per selezionare il dispositivo radice previo uso del comando root, caricare l’immagine statica di un kernel con il comando linux, in caso di necessità permette il caricamento di moduli addizionali per il kernel con il noto comando insmod e, come ultima fase, l’avvio del sistema operativo con il comando boot. Quanto riportato è quello che poi, in sintesi, accade nel momento in cui il programma va a leggersi il file di configurazione presente in /boot/grub2/grub.cfg la cui sintassi è di fatto un linguaggio di scripting shell-like e in quanto tale caratterizzato da dichiarazioni e funzioni. A differenza del file di configurazione menu.lst di Grub Legacy, il file grub.cfg non deve essere editato manualmente ma l’editing sarà automatico ad ogni aggiornamento.
È permesso invece modificare manualmente file come /etc/default/grub per il controllo di parametri come l’aspetto del menu di GRUB. Possibile anche la modifica manuale degli script, ed eventualmente aggiungerne di nuovi, presenti nella cartella /etc/grub.d/. Tali script permettono il controllo di applicazioni come memtest, aggiunta di altri sistemi operativi ecc. Va da se come occorra un minimo conoscere la sintassi degli shell scripting per attuare una qualsivoglia modifica e quanto meno sapere cosa si sta facendo! Ogni modifica, affinchè venga riportata nel file di configurazione e renderla così attiva, va confermata con il comando update-grub2 che naturalmente dovrà essere impartito con le credenziali dell’amministratore (o utilizzando sudo per quelle distribuzioni che lo abilitano in maniera predefinita).
Altre nozioni su GRUB verranno date al bisogno nel seguito, in ogni caso è sempre possibile consultare il manuale on-line di GRUB 2 scritto in una maniera molto comprensiva e tale da scorrere abbastanza velocemente senza perdersi in ghirigori di parole andando subito al punto.
Prime informazioni
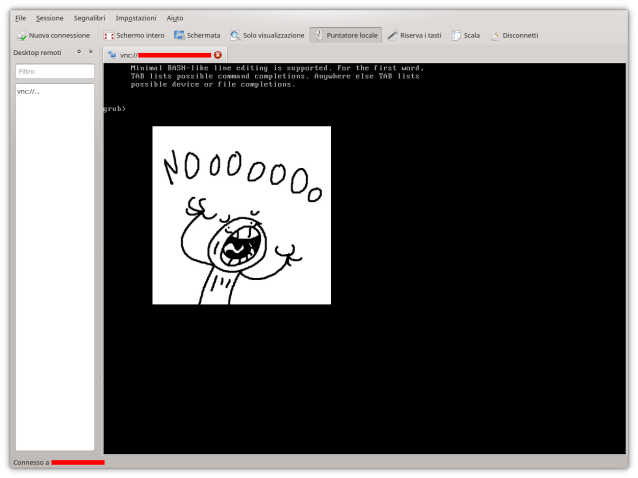
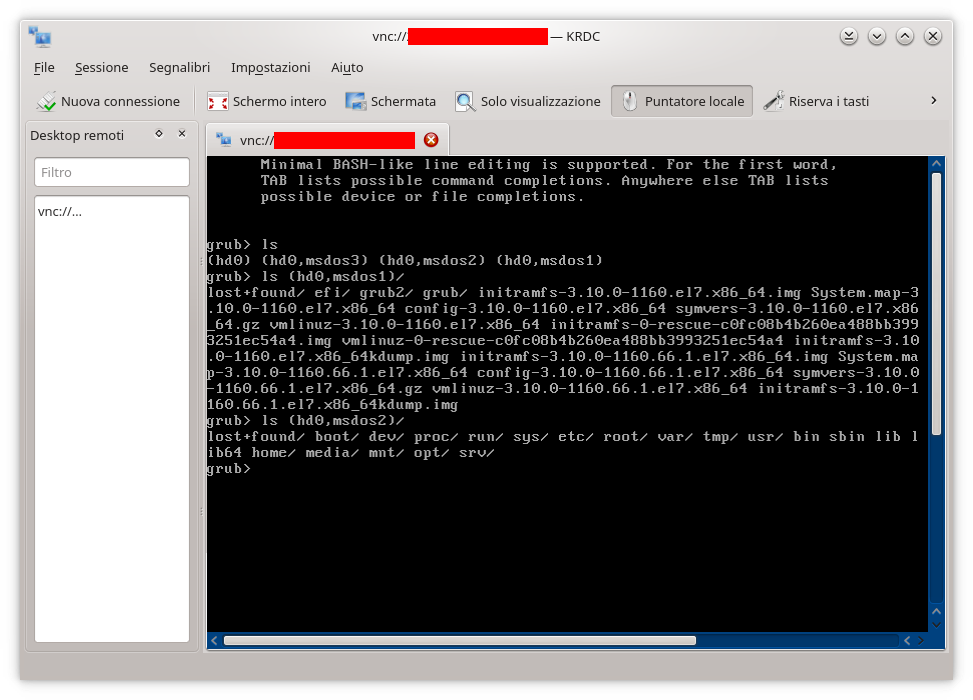
Eseguito l’accesso via VNC previo uso del programma KRDC a corredo del desktop KDE, (ma qualunque programma va bene, e.g. Vinagre dell’ambiente del piedone Gnome o altri anche a linea di comando) subito viene presentato il prompt del bootloader GRUB (immagine in alto).
- Il processo di avvio del sistema si interrompe su una schermata con il prompt GRUB;
- Il server si blocca ad un successivo riavvio sempre sul prompt grub>.
Pertanto non ha senso continuare a riavviare il server. Come procedere? Quando viene avviato il sistema e si ferma al prompt di grub>, occorre sapere che questa è la shell dei comandi completa di GRUB 2. Ciò significa che GRUB 2 si è avviato regolarmente, ha caricato il modulo normal.mod così come altri moduli necessari all’avvio presenti ad esempio in /boot/grub2/i386-pc/ (se in uso è il tipico PC BIOS) ma ha riscontrato qualche problema sul file grub.cfg oppure …non è riuscito proprio a trovarlo il file grub.cfg! Se invece GRUB 2 si dofosse bloccato sul prompt grub rescue> significa che non è riuscito a trovare nemmeno il modulo normal.mod e con molta probabilità nemmeno gli altri moduli e file di avvio! Nella modalità rescue (recupero) solo un sottoinsieme di comandi sono disponibili rispetto alla modalità a linea di comando tra i quali si vogliono ricordare; insmod, ls, set e unset.
Arrivato a questo punto è noto solo che ci viene presentata la shell dei comandi completi (l’elenco completo è riportato nella documentazione ufficiale). Non ricordo il partizionamento del disco (virtuale o reale che sia) del server pertanto la prima cosa è capire com’è strutturato. Ricordo che, a differenza della scelta predefinita di CentOS nella fase di installazione, non fa uso di LVM (Logical Volume Manager) pertanto mi devo aspettare delle “classiche” partizioni, ma di che tipo?
Poiché si è già in modalità linea di comando di GRUB il tasto TAB elencherà tutti i comandi disponibili, ma al momento non ne occorrono tanti poiché il primo obiettivo è capire il partizionamento del disco. GRUB mette a disposizione il comando ls (contrazione della parola LiSt) il quale, impartito senza argomenti, fornisce l’elenco delle partizioni presenti sul disco; nel caso in parola, come anticipato, si fa uso della vecchia modalità MBR (Master Boot Record) del BIOS (Basic Input/Output System) poiché l’elenco vede una struttura del tipo (hdX,msdosY) dove X e Y identificano rispettivamente il numero del disco e il numero della partizione. Viceversa in presenza di partizioni di tipo GPT (GUID Partition Table) dello standard EFI (Extensible Firmware Interface) l’output sarebbe stato qualcosa del tipo (hdX,gptY) con X e Y significato analogo al precedente.
Ora che si conoscono le partizioni del disco è possibile passarle come argomento al medesimo comando. Ad esempio ls (hd0,msdos1)/ evidenzia che trattasi della partizione /boot poiché contiene le cartelle EFI, grub2, i diversi file del kernel e della sua configurazione, del ramdisk e noti file contenuti in questa cartella. Va da se che una delle due partizioni rimanenti non può che essere la root (la / e non la /root!) e probabilmente la swap. Un veloce ls (hd0,msdos2)/ evidenzia la tipica struttura del filesytem con le varie cartelle.
Passaggio del kernel da lanciare
A questo punto occorre capire da dove arrivi il problema; file del kernel corrotto oppure a esserlo è il file del ram disk, o entrambi? Si è corrotta la configurazione del bootloader GRUB? O un insieme di queste cose? L’unica è tentare un “primitivo” avvio e leggere eventuali errori.
Con GRUB rescue, così come nella modalità CLI (Command Line Interface) nella quale ci si trova, è possibile “precaricare” un kernel per provare a lanciarlo. Per questo occorre fare riferimento al contenuto e al percorso della cartella /boot. In questa fase due sono i file di interesse. Il primo è quello del kernel di nome vmlinuz-<versione>.x86_64 il quale identifica l’immagine statica del kernel (convenzionalmente presenta questo nome) e vede al suo interno la presenza dei moduli compilati staticamente all’atto della configurazione della distribuzione nel momento in cui viene rilasciata dagli sviluppatori. Il secondo file di interesse verrà richiamato tra breve.
Per passare il kernel da lanciare si può fare uso, come anticipato, del comando linux con la seguente riga seguita da Invio. Per il caso in questione:
linux (hd0,msdos1)/vmlinuz-3.10.0-1160.66.1.el7.x86_64
È sufficiente il solo passaggio del kernel? Generalmente no, perché se ci si fermasse qui e si tentasse l’avvio molto probabilmente si andrebbe incontro al classico errore Kernel panic poiché potrebbe mancare il modulo per effettuare il montaggio del filsystem. Quanto osservato porta al passo successivo.
Il ramdisk (ramdev)
Il secondo file da prendere in considerazione in fase di avvio, e nello specifico quando si tenta un avvio manuale, è il ramdisk/ramfilesystem presente nella cartella /boot e generalmente oggi di nome initramfs-<versione>.img laddove <versione> coincide con le versioni del kernel installate; per ogni immagine statica del kernel esiste un ramdisk. Ma cos’è e a cosa serve esattamente questo file e perché è così importante, di fatto indispensabile, nella fase di avvio?
Proviamo a vedere la cosa un po’ da “lontano”. Il file vmlinuz-<versione>.x86_64 passato a GRUB rescue visto nel paragrafo precedente altro non è che l’immagine statica del kernel che si ottiene in seguito alla compilazione dello stesso, nel caso in questione da chi sviluppa e in seguito distribuisce la distribuzione GNU/Linux, ma può essere anche l’utente “comune” a patto che sappia cosa stia facendo! Infatti la compilazione del kernel “di per se” non è una procedura complicata. Andando a stringere, la dinamica vede il dare quei 5-6 comandi uguali ogni volta.
Il vero punto quando si tocca il kernel è la sua configurazione, l’abilitazione o meno di specifici moduli per il supporto a periferiche, protocolli di rete, tecniche di virtualizzazione e molto altro ancora. Altra decisione importante riguarda l’abilitazione dei suddetti moduli in modalità statica che ne comporta l’inclusione diretta nell’immagine statica – quindi nel file vmlinuz-<versione>.x86_64 caricato in RAM nella fase di avvio – oppure come moduli esterni caricabili in memoria al bisogno, memorizzati nel filesystem e in quanto tale disponibili solo dopo aver effettuato il montaggio della partizione dove risiedono, nel percorso /lib/modules/<versione-kernel>/.
Il modulo o i moduli interessati a determinate funzioni che devono essere attive già nella fase di avvio (e.g. il supporto al filesystem in uso) non possono essere presenti come moduli caricabili a run-time. Infatti, se si pensa ad esempio al filesystem, come farebbe il kernel a richiamare il suddetto modulo per montare la partizione se la medesima dovrà essere prima montata per usufruire del modulo? A tutto questo si deve aggiungere il supporto al dispositivo hardware in uso (dove viene creato il filesystem) nonché il supporto al protocollo da utilizzarsi (e.g. SATA piuttosto che PATA). Va da se allora che tutto il necessario dovrebbe trovare posto all’interno dell’immagine statica del kernel caricata in RAM nelle prime fasi dell’avvio. Diversamente quando la palla viene passata al kernel, mancando esso del modulo indispensabile a montare la partizione radice, si avrà un’interruzione della fase di avvio con il richiamato errore Kernel panic.
Tale problema è meno sentito dall’utente “comune” che può effettuare delle personalizzazioni specifiche e inserire nell’immagine statica tutto ciò che gli piace, ma quando una distribuzione, e quindi i programmatori che la sviluppano, deve rilasciare un kernel che si possa e debba adattarsi a qualsiasi tipo di macchina allora si adotta una altra tecnica che è quella del ramdisk.
In principio era il file initrd contrazione/acronimo di INIT(ial)R(am)D(isk), un ramdisk iniziale che all’atto pratico è un sistema minimale (da crearsi ad-hoc) caricato in RAM durante la fase di avvio contenente tutti i moduli necessari a compiere un certo numero di operazioni tra le quali il montaggio del filesystem della cartella radice. Attenzione però, occorre far notare che a questo livello è montata si la radice del filsystem ma quella provvisoria del ramdisk e non quella presente sul disco (hard disk o SSD che sia). Per tale motivo, dopo questa prima fase, attraverso la chiamata di sistema pivot_root (per approfondimenti consultare il mauale on-line con i comandi man 2 pivot_root e man 8 pivot_root), viene effettuato il cambio di radice a quella reale, del filesystem sul device di storage seguita dalla successiva liberazione della memoria RAM dal file del ramdisk (a questo livello il ramdisk non serve più poiché si ha a disposizione il filesystem su disco quindi che senso avrebbe mantenerlo in memoria?).
In questa dinamica così come nell’uso intrinseco di initrd vi sono diversi svantaggi. Prima di tutto initrd è a tutti gli effetti un dispositivo a blocchi (come un hard disk, penna USB ecc) e in quanto tale è necessario che il kernel presenti almeno un modulo che ne rilevi e supporti il filesystem, qualunque esso sia (ext2/3/4 ecc). In seconda istanza è di dimensioni fisse pertanto ha poca flessibilità in termini di aggiornamento. Ma esiste un altro importante motivo, tutte le operazioni (lettura/scrittura) su un’immagine initrd vengono memorizzate nel buffer andando a occupare la memoria principale del sistema.
Occorre infatti sapere che il filesystem è rappresentabile sostanzialmente con 3 livelli. Il livello più alto è il VFS (Virtual FileSystem) che fornisce tra le altre cose la funzione di interfaccia tra i programmi utenti e il sistema sottostante a sua volta caratterizzato dai due livelli rimanenti. Il primo vede i moduli necessari alla gestione del filesystem in uso (e.g. modulo per il supporto al filesystem ext3 piuttosto che a btrfs ecc) e l’ultimo livello è di fatto l’interfaccia software-hardware per i dispositivi a blocchi; dispositivi fisici come hard disk, penna USB e schede di memoria (discorso a parte va fatto per le interfacce di rete). Il tutto secondo gli schemi di principio riportati nelle due figure che seguono. Schema più generico a sinistra e con qualche particolare in più a destra. Va da se che altre rappresentazioni più puntuali, specifiche complete anche di eventuale codice è possibile trovarle in rete, ma in ogni caso esulano dal seguente contesto.
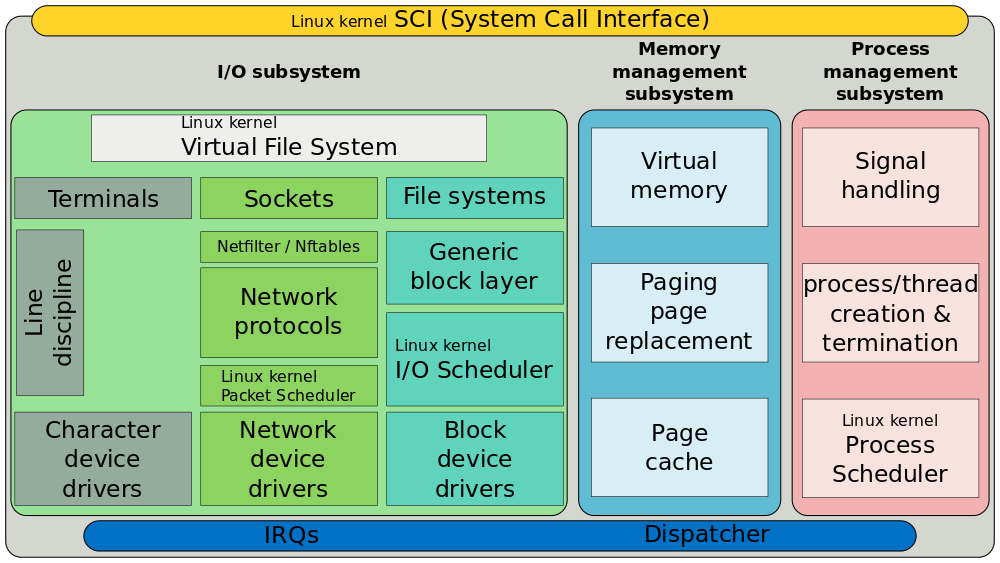
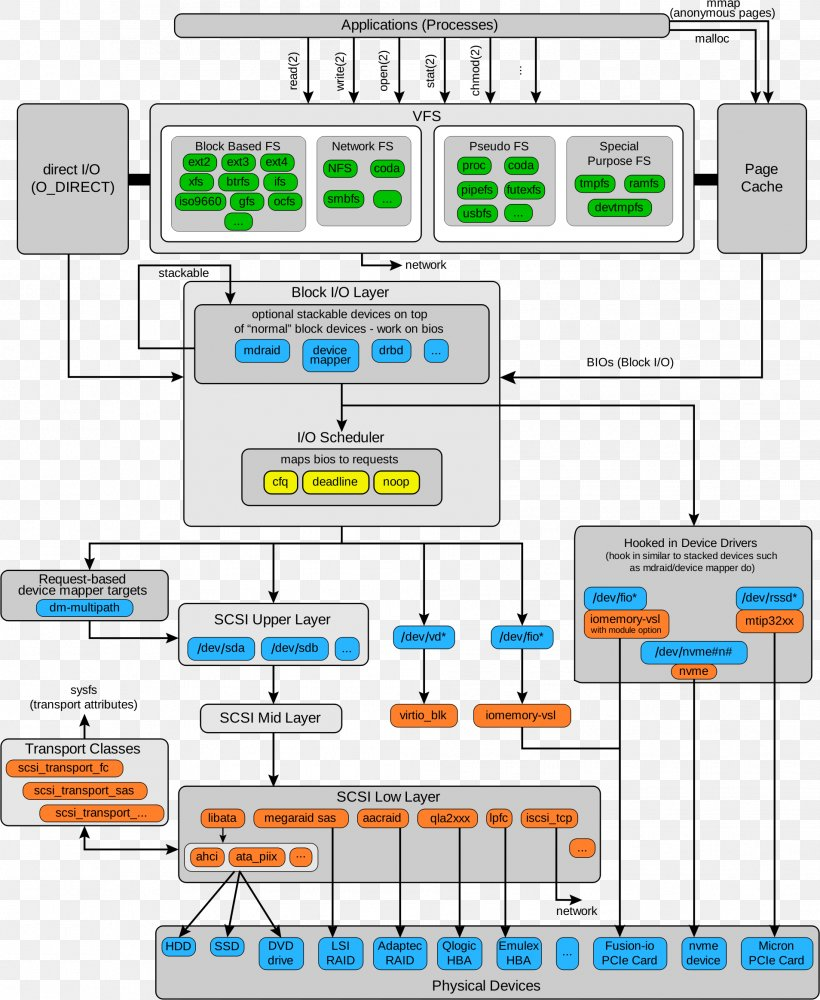
Ora, come si può constatare dalla documentazione ufficiale, andando a stringere di molto, vi sono sostanzialmente 3 elementi (oggetti) principali che entrano in gioco nel VFS; l’oggetto inode, l’oggetto dentry e l’oggetto file. Trattasi, ovviamente, non di classi poiché il linguaggio è il C, ma di strutture organizzate a mo’ di classi. In estrema sintesi:
- inode – È l’oggetto, la struttura attraverso la quale il kernel Linux identifica univocamente tutti gli elementi nel filesystem. Ogni inode (contrazione di Index NODE) può quindi fare riferimento ad un file, una cartella o un link simbolico. Poiché un file è utilizzato in GNU/Linux per poter rappresentare altri elementi dai file propriamente detti (e.g. dispositivi a blocchi e a caratteri), allora un inode viene utilizzato anche per rappresentare tali elementi. Essendo l’inode una struttura, i suoi campi descrivono una serie di parametri e operazioni possibili nonché diversi metadati come i tempi di creazione, accesso e modifica, i permessi, le operazioni possibili inerenti le possibili e autorizzate chiamate di sistema (e.g. le classiche open, write, read, flush ecc).
- dentry – Contrazione/acronimo di Directory ENTRY è la struttura che utilizza il kernel Linux per tenere traccia della gerarchia dei file nelle cartelle (directory). Una dentry è il collante tra le strutture inode e file relazionando il numero dell’inode con il nome del file. Altra proprietà delle dentry sono i permessi sulle directory e quindi di riflesso la possibilità di “attraversamento” nel filesystem ad opera degli utenti.
- file – Probabilmente la struttura più intuitiva poiché è tutto ciò che un essere umano può pensare nel momento in cui legge/sente la parola file. La struttura file memorizza le informazioni dell’interazione tra un file aperto e il processo che lo impegna. Tali informazioni permarranno nella memoria kernel per tutto il tempo necessario al processo, finché ne necessiterà e non opterà per la sua chiusura.
Appare chiaro come per ogni file aperto a qualsiasi livello di cartella (e.g. nidificate o meno) dovranno esserci strutture inode e dentry allocate nella memoria kernel che le possano rappresentare.
Il sopra richiamato VFS ha un’altra funzione relazionata alle performance del sistema. I blocchi fisici del disco più acceduti sarebbe il caso che venissero memorizzati opportunamente affinché possano essere richiamati all’occorrenza senza la necessità di andare ogni volta ad eseguire una lettura su disco (dispositivo notoriamente più lento rispetto ad altre soluzioni). La tecnica utilizzata per questa funzione è quella della cache, e.g. dentry cache, inode cache ecc. Ad esempio la dentry cache mantiene in memoria gli oggetti dentry che rappresentano i percorsi del filesystem, la inode cache memorizza gli oggetti inode corrispondenti agli inode del disco, parti fondamentali della cosiddetta cache del disco la quale, a partire dalla versione 2.4.10 del kernel è definita come page cache (in versioni precedenti esisteva anche la buffer cache come elemento indipendente poi “confluita” nella page cache).
Normalmente il kernel fa riferimento alla page cache durante le fasi di lettura/scrittura su disco. Nuove pagine vengono aggiunte alla page cache al fine di soddisfare le richieste di lettura dei processi in modalità utente. Se i dati richiesti non sono presenti nella page cache viene aggiunta una nuova “entry” e riempita con i dati letti su disco. Tali dati possono riguardare pagine contenenti file regolari, pagine contenenti directory, pagine contenenti dati letti direttamente da dispositivi a blocchi e altre tipologie di dati che in questo contesto non interessano.
Se c’è abbastanza memoria libera la pagina viene conservata nella cache per un periodo di tempo indefinito al fine di essere riutilizzata da altri processi senza necessità alcuna di accedere al disco. Va da se che se lo spazio occupato dovesse rendersi necessario per altro scopo la voce verrà rimossa.
Questa lunga premessa sul VFS si è resa necessaria poiché il file initrd essendo un dispositivo a blocchi ram-based comporta e da luogo ad un importante sovraccarico sulla CPU, risorse RAM e disco più in generale, dovuto alle multiple page-in (lettura disco per portare in page cache ciò che ancora non è presente) e page-out (liberazione della memoria per altri scopi).
Ricapitolando per punti la dinamica:
- Il bootloader GRUB 2 esegue le istruzioni necessarie per caricare in RAM il file dell’immagine statica del kernel e del file initrd;
- A questo punto il file initrd viene decompresso ed estratto al fine di avere a disposizione un filesystem temporaneo che viene convertito dal kernel in un RAM disk montato in /dev/ram come filesystem radice, operazione resasi necessaria per poter accedere ai driver indispensabili per rilevare il file system originale su supporto fisico ed eseguirne il mounting che permetterà il cambio di radice a quella reale con la richiamata funzione pivot_root;
- Viene quindi richiamata l’esecuzione del gestore di servizi del sistema; una volta era /sbin/init oggi, laddove presente con il medesimo nome, è un alias ad un eseguibile della galassia systemd al fine di portare a termine la fase di avvio.
- Viene liberata la memoria dall’ingombrante presenza di initrd; al punto al quale è arrivato l’avvio risulta del tutto inutile, il suo compito oramai l’ha svolto. La verifica è possibile con il comando dmesg | grep initrd il quale fornirà un’uscita del tipo [0.734646] Freeing initrd memory: 14540K o qualcosa di simile.
I ram filesystem
La dinamica riportata nel precedente paragrafo, ad esclusione ovviamente del cenno a systemd, si è avuta fino alla versione 2.6.x del kernel a partire dalla quale il file initrd è stato dapprima deprecato per poi essere subito sostituito da un nuovo meccanismo chiamato initramfs contrazione/acronimo di INIT(ial)RAMF(ile)S(ystem). L’obiettivo finale è sempre il medesimo; initrd e initramfs sono due metodi diversi attraverso i quali un file system temporaneo deve essere reso disponibile al kernel.
Un filesystem basato su memoria ram intuitivamente è una metodologia che crea un’area dove immagazzinare i dati direttamente nella memoria RAM del computer, alla stregua di una partizione su disco. Una prima differenza sostanziale risiede nella velocità di accesso che risulta essere decisamente superiore rispetto ad un “disco convenzionale”. GNU/Linux permette di realizzare un filesystem in memoria RAM secondo due distinti modi che vanno sotto il nome di ramfs e tmpfs. Entrambi svolgono il medesimo compito ma con sottili e importanti differenze.
Ramfs
Filesystem in memoria RAM con due caratteristiche sostanziali. La prima. Il filesystem viene creato utilizzando la memoria cache allo stesso modo con cui GNU/Linux utilizza la cache durante le normali operazioni. La seconda, ramfs è caratterizzato da una crescita dinamica via via che viene richiesto sempre più spazio da chi ne fa uso.
Questo comportamento implica una crescita incondizionata fino ad occupare tutta la memoria RAM condizione per la quale il sistema inizierà a rallentare prima e successivamente ad essere meno o non responsivo con evidenti problemi per quelle applicazioni che ne fanno uso e che possono portare il sistema al blocco.
Non è possibile utilizzare il comando df -h per valutare la dimensione di un ramfs. Sarebbe possibile stimarne la dimensione con il comando free verificando la voce buffer/cache nell’output. In ogni caso non se ne potrà conoscere la dimensione esatta.
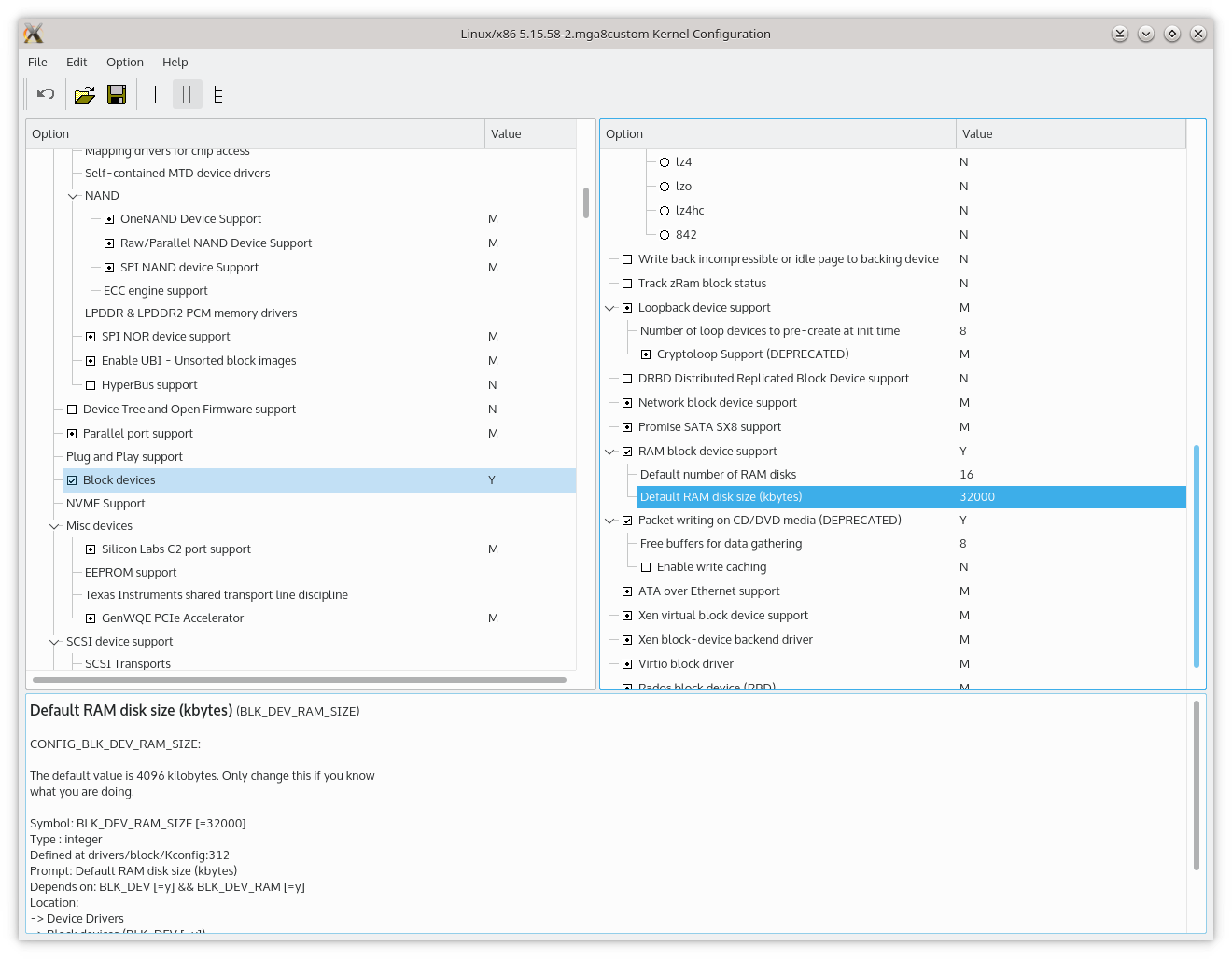
Per tale motivo in GNU/Linux è possibile impostare una dimensione massima e fissa per il ramfs previo utilizzo di una opzione che può essere vista come parametro di configurazione del kernel così come parametro da passare al bootloader (man 7 bootparam per approfondimenti). Il riferimento è a ramdisk_size=dim il cui valore predefinito è pari a 4MB. Tale opzione è in realtà un parametro del modulo del kernel di nome brd (qui il sorgente brd.c) le cui informazioni è possibile ottenerle con il comando modinfo brd.
Il suddetto parametro è presente come opzione di configurazione del kernel nel percorso Device drivers →Block devices →RAM block device support come riportato nell’immagine in basso nella quale va ricordato che la GUI (Graphical User Interface, l’interfaccia grafica) visibile viene ottenuta impartendo dall’interno dei sorgenti del kernel il comando make xconfig.
Tmpfs
Questo ram filesystem supera alcuni limiti di ramfs. In primis, come ramfs, in tmpfs è possibile specificarne la dimensione ma, a differenza di ramfs, se durante l’uso viene superato il valore prefissato verrà restituito un errore del tipo No more free space, Disk full o simili alla stregua di una comune partizione disco che si è riempita di file. Altra differenza tra ramfs e tmpfs è che quest’ultimo una volta creato lo si può visualizzare con il comando df -h. Le proprietà riportate rendono tmpfs molto più maneggevole, flessibile e sicuro rispetto a ramfs. Come se non bastasse tmpfs ha un’ulteriore proprietà; se il sistema operativo, per vari motivi, ha terminato la memoria RAM a disposizione, tmpfs andrà ad utilizzare lo spazio swap su disco.
Dal punto di vista prestazionale non c’è differenza tra i due ram disk, a patto che tmpfs non stia utilizzando lo swap su disco! La differenza invece è nella modalità di allocazione della memoria che risulta essere “al volo” per tmpfs il che tende a frammentare non poco la RAM che gli viene permessa di allocare. Non è così per ramfs il quale, essendo un dispositivo a blocchi, alloca la memoria in singoli blocchi.
Allora durante la fase di avvio il file immagine costituito da initramfs, che sostituisce initrd, una volta caricato in memoria RAM viene decompresso e spacchettato dal kernel e nel compiere questo operazione utilizza anche una istanza temporanea di tmpfs che diventa così anche la radice del file system per il tempo necessario. Occorre qui ricordare/ribadire come tmpfs non abbisogni di un modulo specifico per funzionare, è natio e sempre attivo nel kernel pertanto nessun dispositivo e/o nessun driver aggiuntivo si rende necessario. Questo è il punto di forza che di riflesso comporta che, a differenza di initrd, non è più necessario inserire nell’immagine statica del kernel il supporto per nessun filesystem specifico. La dinamica è praticamente analoga a quella elencata per punti nel paragrafo precedente con l’unica differenza che la funzione necessaria a compiere la commutazione dal filesystem radice su tmpfs al filesystem su supporto viene ottenuta con la funzione switch_root (man 8 switch_root per approfondimenti).
Dal punto di vista pratico l’immagine/file initramfs altro non è che un archivio cpio compresso generalmente con gzip. In alcuni casi per la compressione può essere utilizzato anche XZ. Per poterlo analizzare come primo passo si copia il file immagine in una cartella temporanea nella propria home utente ad esempio con:
# cp /boot/initrd-5.15.62-desktop-1.mga8.img /home/nome_utente/tmp
Da osservare come l’operazione di copia debba essere condotta con i permessi dell’amministratore, o quanto meno utilizzando sudo per le distribuzioni che lo abilitano di default, poiché i permessi del file sono impostati a 600 con utente e gruppo entrambi a root. Si entra nella cartella di copia con cd /home/nome_utente/tmp e se ora si provasse ad utilizzare il comando cpio per l’estrazione, ad esempio con cpio -ivF initrd-5.15.62-desktop-1.mga8.img si potrebbe osservare come di un file di circa 14MB solo una piccola parte, una decina di KB, verrebbero estratti. Come mai? Il motivo è dato dal fatto che il file immagine è caratterizzato da multipli archivi cpio compressi e non compressi.
Allora quale deve essere la dinamica da seguire per poterne analizzare struttura e contenuto? Per procedere allo spacchettamento del file è sufficiente eseguire l’operazione inversa della costruzione e, come accade nel mondo GNU/Linux, vi è più di un modo per poter arrivare alla soluzione; nel seguito ne verrà illustrato uno. La prima cosa è cercare di saperne qualcosa in più sul file immagine che si vorrebbe aprire e per farlo ci si può avvalere del comando (omonima utility) binwalk in genere a corredo dei repository delle distribuzioni. Il comando binwalk initrd-5.15.62-desktop-1.mga8.img fornirà diverse informazioni (immagine in basso). Nello specifico si nota come esso sia composto da due sezioni; la prima di dimensioni ridotte carattrerizzata da un archivio cpio non compresso e una seconda molto più corposa costituita da un archivio cpio compresso XZ. Ma l’uscita del precedente comando cpio ha fornito in uscita la grandezza della prima sezione pari a 18 blocchi (nel caso in questione). Allora si può pensare di dividere le due sezioni isolando la parte più corposa operazione ottenibile con
# dd if=initrd-5.15.62-desktop-1.mga8.img skip=18 of=initramfs_main
il quale salterà a piè pari i primi 18 blocchi del file initrd-5.15.62-desktop-1.mga8.img (opzione skip) e copierà tutto il resto nel file di uscita nominato initramfs_main (ma qualunque nome va bene). A questo punto il comando ls -l confermerà la creazione del comando initramfs_main mentre il comando file initramfs_main la sua tipologia che può essere verificata in maniera più accurata con binwalk initramfs_main i quali mostrano un archivio cpio compresso gzip. Allora si può pensare di decomprimere il file usando zcat e passando l’output in pipe (simbolo |) direttamente a cpio al fine di estrarre anche l’archivio:
# zcat initramfs_main | cpio -iD main_initramfs
che estrarrà tutto il contenuto nella cartella main_initramfs che dovrà essere preventivamente creata con il comando mkdir main_initramfs. Le due immagini in basso illustrano tutta la procedura e relativi output. Da notare come alcune alcune distribuzioni continuino a chiamare il file initramfs come initrd, è il caso ad esempio di Mageia e qualche derivata Ubuntu ma non è il caso della CentOS dei suoi fork come Rocky Linux o AlmaLinux. e altre distribuzioni più o meno note.


È possibile utilzizare un unico comando per esaminare il contenuto del file initramfs/initrd e di preciso lo script lsinitrd (a volte link simbolico a lsinitramfs o il contrario) del pacchetto dracut. Molto semplicemente – immagine in basso – con lsinitrd initrd-5.15.62-desktop-1.mga8.img | more impartito con le credenziali dell’amministratore (o anteponendo il comando sudo).
Primo tentativo fallito, ma…
Dopo aver passato il file del kernel alla shell di GRUB, così come riportato in precedenza, è ora di tentare un avvio non prima, però, di aver passato il file del ramdisk. Per il server in parola :
initrd (hd0,msdos1)/initramfs-3.10.0-1160.66.1.el7.x86_64.img
boot
l’ultima riga istruirà GRUB ad eseguire l’avvio con i parametri passati (versione del kernel e file del ramdisk). Quando si digitano i comandi, i percorsi e/o nomi dei file ci si può aiutare con il completamento automatico supportato dalla shell GRUB attraverso il tipico tasto TAB. Va inoltre ricordato che in questa fase la mappatura della tastiera normalmente non è Italiana pertanto diversi tasti potrebebro non corrispondere, i.e. il simbolo – (dash) va fatto pigiando il tasto del ?, la parentesi tonda aperta ( come Shift-), la parentesi tonda chiusa come Shift-0 ecc.
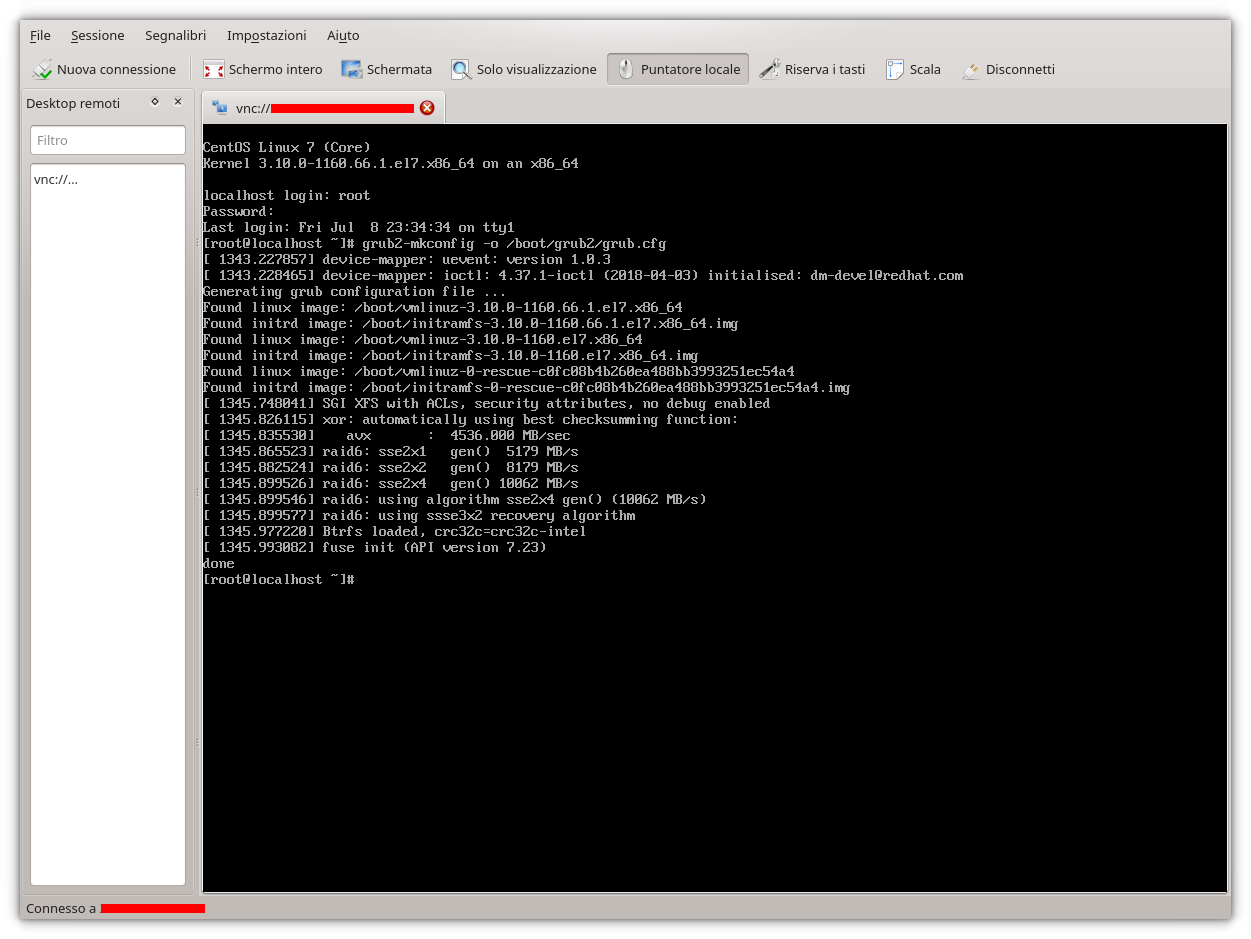
Risultato del tentato avvio? Visibile in basso.
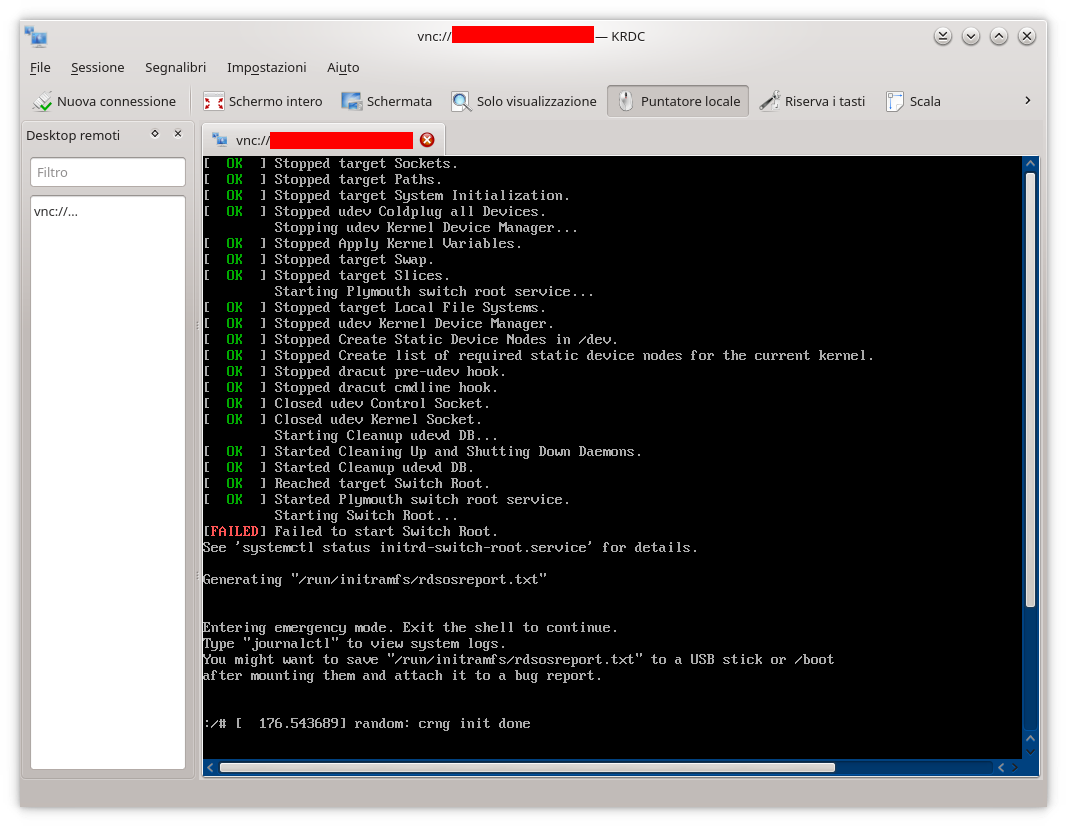
Il sistema si avvia (evviva 🙂 ) ma (sic!) termina con l’errore Failed to start switch root e il comando indicato dal sistema, ovevro systemctl status initrd-switch-root.service, non fa altro che confermarlo.
Non resta che esaminare il file di log rdsosreport.txt che è stato creato nel percorso indicato /run/initramfs/ e lo si può fare utilizzando, ad esempio, il comando cat (man cat per approfondimenti) a cui aggiungere, al fine di agevolarne la lettura, il paginatore less in pipe, in pratica cat run/initramfs/rdsosreport.txt | less. Comunque è sempre possibile utilizzare un editor di testi tra quelli installati e.g. vi run/initramfs/rdsosreport.txt. Qualunque sia la scelta la lettura del suddetto file di log mostra, e riporta, l’errore:
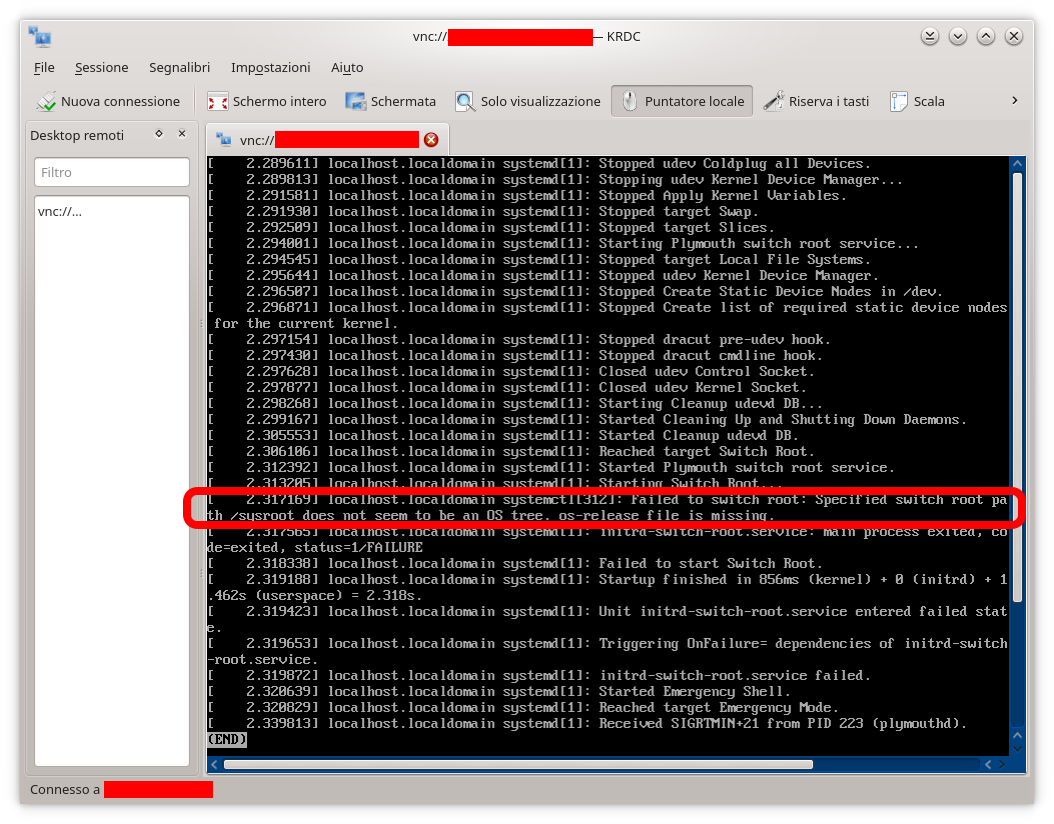
Failed to switch root: Specified switch root path ‘/sysroot’ does not seem to be an OS tree. os-release file is missing.
come riportato nell’immagine in basso a sinistra, ad indicare chiaramente che non c’è nulla montato come /sysroot e pertanto il sistema non potrà mai trovare il file di nome os-release riportato e in quanto tale viene indicato come missing (mancante). Ma c’è di più, il citato file di log fornisce la medesima informazione nelle primissime righe dove viene riportato l’output del comando cat /proc/cmdline il quale mostra i parametri passati al kernel all’atto dell’avvio ovvero (parte cerchiata in rosso immagine in basso adestra):
BOOT_IMAGE=(hd0,msdos1)/vmlinuz-3.10.0-1160.66.1.el7.x86_64
ma non si vede nessuna riga del tipo:
root=UUID=54f24598-4a21-4875-bacd-61c060de891f
laddove UUID indica lo Universally Unique IDentifier della partizione di root (il riferimento è sempre alla / e non alla /root dell’omonimo utente!). Naturalmente altre partizioni avranno diversi UUID e per rendersene conto è sufficiente impartire il comando blkid senza argomenti il quale stamperà a video gli attributi (e.g. etichetta della partizione, percorso del montaggio, tipo di filesystem ecc) dei dispositivi a blocchi (man blkid per approfondimenti).
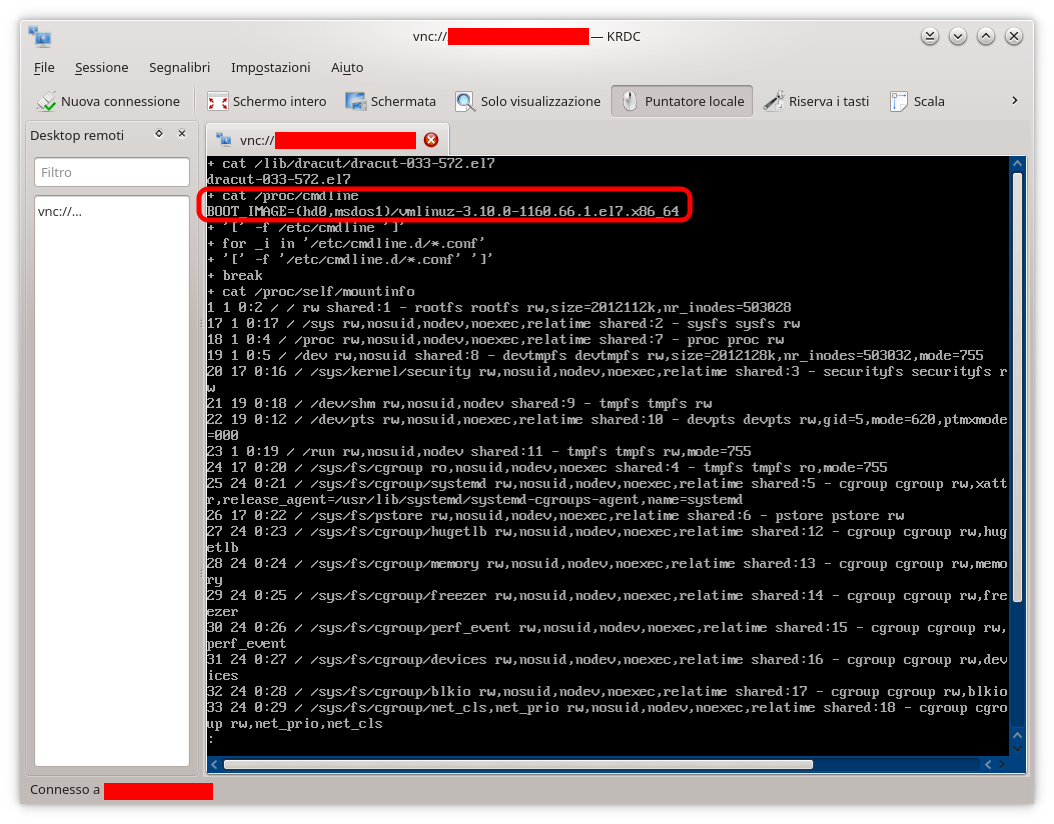
A fronte di un errore si può osservare come l’avvio venga tentato e non può che essere una buona notizia. Allora perché quell’errore? I più attenti avranno già notato che i parametri passati a GRUB sono stati il kernel e il ramdisk ma proprio nel kernel manca l’indicazione della partizione radice la quale, attraverso il comando blkid, risulta essere associata al device /dev/sda2.
Per verificare quanto ipotizzato si esegue un riavvio della macchina con il comando reboot che ovviamente riporterà nuovamente sulla shell GRUB e nella quale si dovranno nuovamente impartire i comandi delle 3 righe precedenti solo che in questo caso la prima va modificata come segue:
linux (hd0,msdos1)/vmlinuz-3.10.0-1160.66.1.el7.x86_64 root=/dev/sda2 ro
initrd (hd0,msdos1)/initramfs-3.10.0-1160.66.1.el7.x86_64.img
boot
Dopo aver premuto Invio nell’ultimo comando …voilà, la shell di login! 🙂
Riparare il “guasto”
Quanto riportato risolve l’avvio temporaneo, ma se si provasse a riavviare il server si presenterebbe il medesimo problema perché, in questo frangente, si è avuta una corruzione nel file di configurazione di GRUB che pertanto occorrerà ricreare.
È evidente come il problema sia da imputare a GRUB perché se fosse il kernel o il file initramfs il sistema avrebbe riportato un altro errore e/o non sarebbe partito per niente! Infine, poiché GRUB non entra nella modalità rescue (recupero) allora anche tutto il resto come moduli e file di controllo vengono regolarmente trovati e caricati laddove necessario.
Tutto quello che occorre fare è ricreare il file di configurazione di GRUB. In genere viene suggerito il comando, con ovvio significato, update-grub il quale altro non è che uno script shell presente in /urs/bin il quale è caratterizzato da una sola linea del tipo:
su –login root -c “/usr/sbin/grub2-mkconfig -o /boot/grub2/grub.cfg”
Allora è evidente che un comando alternativo (che di fatto è il contenuto dello script update-grub è:
grub2-mkconfig -o /boot/grub2/grub.cfg
per server basati su RHEL/CentOS che adottano il BIOS. Altrimenti per sistemi RHEL/CentOS “UEFI-based” il comando diventa:
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
Il comando, come visibile nell’output dell’immagine in alto, genera di nuovo il file di configurazione di GRUB. A questo punto il server è di nuovo on-line
Casistica
Come avviene sempre nel mondo GNU/Linux, la dinamica seguita per arrivare alla risoluzione non è detto che risulti essere l’unica possibile anche perché l’errore riportato non sempre può essere indotto dal medesimo problema.
Errori uguali pososno essere indotti da problemi differenti come possibili bug in componenti software non scoperti in fase di rilascio. Un tipico esempio risale a pochi mesi fa nell’aggiornamento di versione della distribuzione commerciale Red Hat (della quale la CentOS ne è una derivata) dove è stato riportato il problema System falls in to emergency mode due initrd-switch-root.service entered failed state risolto con una rigenerazione del file initramfs.
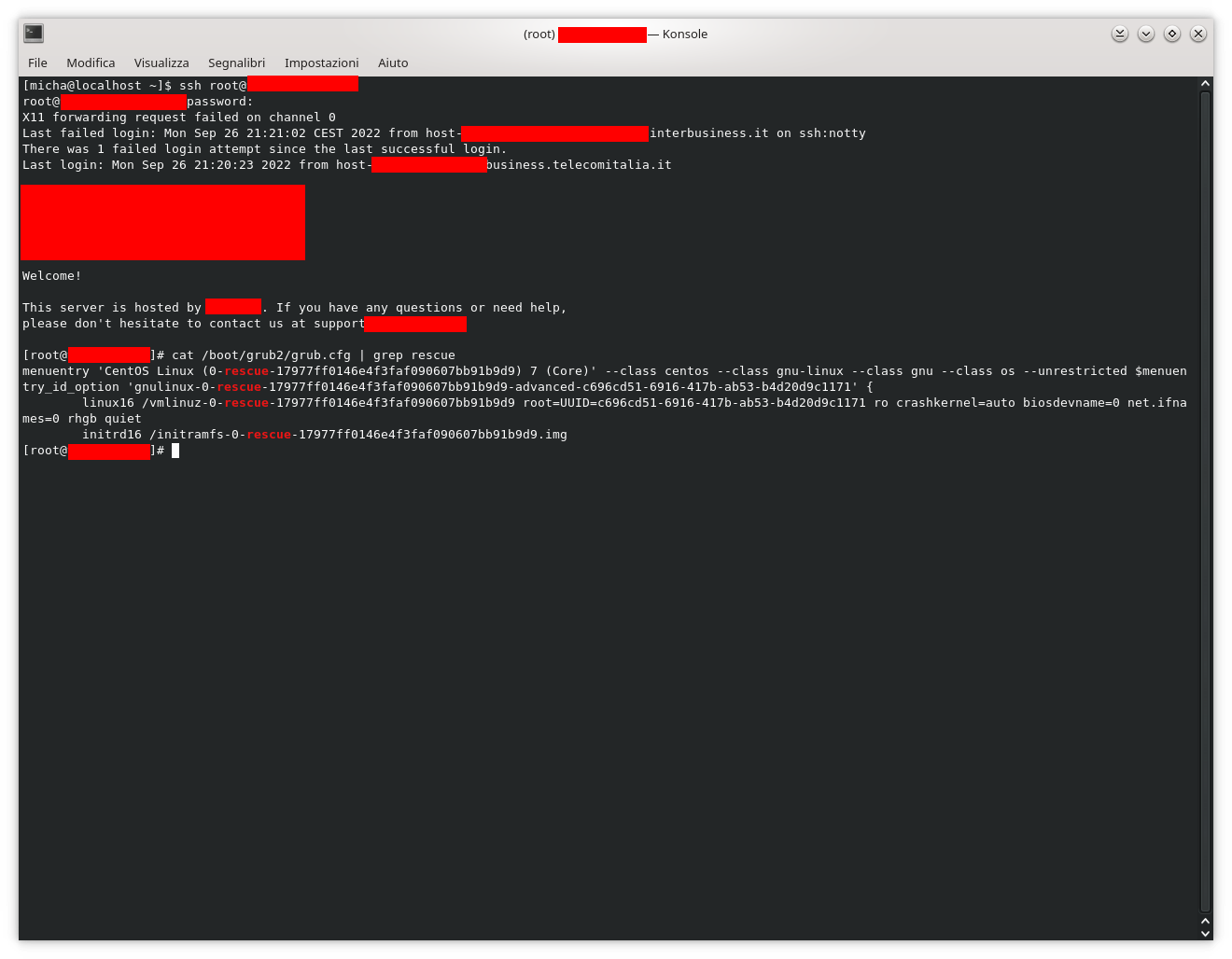
Inoltre occorre considerare che, a seconda della configurazione del proprio server, tra le voci del menù di avvio di GRUB può esserci più di un kernel di scelta per l’avvio, compresi i file rescue (kernel e initramfs, come visibile dalla foto in alto dopo la rigenerazione del file di configurazione di GRUB) per i quali è possibile verificarne la presenza utilizzando,a d esempio, il comando cat /boot/grub2/grub.cfg | grep rescue il quale dovrebbe mostrare un qualcosa simile all’immagine che segue.
Va da se che se la corruzione del file di configurazione di GRUB interessa tutte le voci (i kernel) presenti – come era questo il caso – l’avvio non avverrà nemmeno tentando con altri kernel. Per verificarlo si può sempre far visualizzare il menù principale a GRUB – qualora fosse in grado di visualizzarlo! – e tentare l’avvio con altri kernel (laddove presenti). Se si riesce ad arrivare alla shell di login, ad esempio perché l’errore nella configurazione automatica post aggiornamento interessa solo la versione del kernel appena aggiornata. correggere l’errore rigenerando il file di configurazione di GRUB come riportato nel precedente paragrafo.
Addendum – E se fosse in uso LVM?
In scrittura poiché dovrà essere simulato e verificato dapprima su macchina virtuale prima di scrivere la procedura. 🙂